
- Vol.26-27
- 京都コンピュータ学院55周年・京都情報大学院大学15周年 記念式典・祝賀会を開催
- 躍動! 日本 I T団体連盟
- 初音ミクから学ぶデジタルコンテンツの可能性
- 新型コロナウイルスと持続可能な開発目標(SDGs)
- ニッツァ・メラス教授の京都案内
- KCGでMUΣA Live Show開催
- ジャパンエキスポに参加して
- 情報処理・ITで創る豊かな社会
- 日本のコンピュータ発展の歴史と情報処理学会の取り組み
- 親鸞聖人と私
- ITへの依存を高めるリスク管理
- モンゴルの雑誌“The Defacto Gazette”にキリル・コシック教授のインタビューが掲載
- 次代を担うIT人材育成へ活発に産学連携講義を開講
- 松田聖子の登竜門
- 私と吹奏楽
- 漢詩「哲学の道」
- 漢詩「暁庭聴鶯」
- 漢詩「三十三間堂」
- 卒業生インタビュー ヤンマー株式会社 中央研究所
- 卒業生インタビュー 株式会社イーパス・株式会社シードバンク
- ニュースこの1年「KCG365」
- KCGの浦山さんが情報処理学会で受賞
- インターネット関連の国際会議「ICANN64」に「.kyoto」のKCGIが参加
- 医療情報コースの学生が京都医療センターでインターンシップ
- 「救急災害医療」の特別授業を実施 第一人者の志馬先生から学ぶ
- KCGIからのSAP認定試験合格者が150人突破
- KCG創立者・長谷川繁雄初代学院長先生を偲ぶ「閑堂忌」
- 「KCGサマーフェスタ2019」を開催
- KCG共催の「京まふ2019」に大勢来場
- 移動体の自律走行を支援する高精度測位用基準局をKCGに設置
- モンゴルから来賓迎えKCGでシンポジウム開催
- 「ウィーンピアノ四重奏団演奏会」を開催
- KCG,KCGMの大槻幸雄顧問が日本自動車殿堂入り
- 『ドラゴンクエストX』『ニーア オートマタ』ゲームイベント開催に協力
- ソニーグループ企業によるIT業界セミナーを開催
- フランス総領事とマルセイユ市副市長一行がKCGI・KCG訪問
- KCGIがベトナム国家大学ハノイ校工科大学と交流協定を締結
- 2020年度からKCGI入学定員を600名に 開学時の7.5倍
- 授業料・入学金減免,奨学金支給の対象校に認定
- 訃報
- アキューム26-27(2021年発行)掲載広告
- Vol.25
- バイオ7からモンハンワールドへ KCG卒業生が開発の中心的役割
- アニメと日本と世界
- ジャパンエキスポに参加して
- 初音ミクがなぜ世界で支持されるか
- 日本ユニシスと締結
- 未来環境ラボを開設
- 未来環境ラボ技術交流会
- 京都医療センターと締結
- 京都医療センター見学記
- ポケットカルテ®を医療費適正化の切り札に
- 産業界において今後IT人材の果たす役割と必要なスキル
- ANIAが30周年
- 「KCGは京大が生んだ」長谷川繁雄 初代学院長先生を偲ぶ閑堂忌
- ICTによる社会のスマート化
- 臨場感の誕生:『ブリット』のカーチェイスの表象メカニズム
- 音楽を聴く楽しみについて
- パーソナルコンピュータ博物史の刊行によせて
- 地球の色彩り鑑賞・そら(宇宙)の旅
- 古を語る星ぼし⑦ 暦の計算法
- 集団人間行動と陶器
- 偶然購入した『沫若詩詞選』から見えてきたもの
- Welcome!KCG国費留学生
- KCG校友が京都大学で博士号を取得
- KCGI2017年度春学期学位授与式の最優秀賞は山中勇矢さん
- 漢詩「八達嶺長城」
- 漢詩「詠曼殊沙華」
- ニュースこの1年「KCG365」
- KCGが共催、京まふ大盛況
- プロが求める企画書とは?ゲームクリエイターによるセミナーを開催
- 恒例のKCGサマーフェスタ2017地域住民が多数参加
- 描いた絵と一緒に写真撮ったよ!京都水族館のKCGイベント人気
- KCGIからのSAP認定試験合格者が100人を達成
- 第一人者を招き「救急災害医療」の特別講義を実施
- ゲームエンジン『UnrealEngine4(UE4)』セミナーを開催
- チームラボによるIT業界セミナーを開催
- 米田貞一郎先生安らかに。「琵琶湖周航の歌」やコンサートで偲ぶ
- ロボット動いた!しゃべったよ!KCGで児童対象のプログラミング教室を開催
- インディーゲームフェス「BitSummit」を主催し、出展
- KCGIが韓国の大学等とeラーニング・MOOCの共同研究を開始
- 米国トップビジネススクールの一行がKCGを訪問
- KCGI学生チームがイマジンカップ日本大会に出場
- アキューム25(2018年発行)掲載広告
- Vol.24
- 日本IT団体連盟が誕生
- 情報社会の未来を切り拓くために
- 応用情報学への招待
- 長谷川繁雄初代学院長没後30年
- 新たにPDP-8/IとTOSBAC-1100D「技術遺産認定機器」に
- アメリカ映画と古い仏像
- 蓬莱と徐福
- 漢詩「豊国廟懐古」
- 漢詩「春日郊行」
- けいはんなからの新しいICTの波に乗り,次世代技術への興味を!
- 京都の品格・文化性を体現するよう安全安心な運営
- 古を語る星ぼし⑥安倍晴明の子孫たち
- 世界中の学生をつなぐ歌「君は花 僕は風」
- KCGの学生チームが性犯罪撲滅へアプリを開発し発表
- ディジタル情報の多様性を支える原理
- 訃報 米田貞一郎先生
- ニュースこの1年「KCG365」
- KCGとKCGIが京都府警と人材育成に関する協定を締結
- 「顧客の声聞き新IT展開を」。京情協講演で大元氏
- インディーゲームフェス「BitSummit 2015」を共催し出展
- KCGIが京都府と包括協定を締結,官学連携し京都ブランド発信
- IT声優コース学生に声優のKINAKOさんが指導
- 大連外国語大の学生がKCGIで短期研修
- ERP人材育成に向けKCGとKCGIがクレスコ社と協定締結
- 日本が僅差で台湾破る!CGアニカップに多数のファンがKCGへ
- 京情協,KCGIが企業情報セキュリティ支援ネットワークに参画
- 日本e-Learning大賞・ウェアラブル部門賞に輝いたKCGIを表彰
- 京都廣学館高校と連携協定を調印,出張授業を通じ生徒に専門教育
- KCGIがIPAの「IT起業家育成カリキュラム協力機関」に
- 2016年度からKCGI入学定員を240名に。開学時の3倍
- アキューム24(2016年発行)掲載広告
- Vol.22-23
- KCGグループ創立50周年
- 京都コンピュータ学院創立50周年・京都情報大学院大学創立10周年記念式典
- 式辞 京都コンピュータ学院・京都情報大学院大学統括理事長長谷川亘
- 祝辞 京都情報大学院大学 設立発起人 株式会社堀場製作所 最高顧問 堀場雅夫様
- 祝辞 ボスニア・ヘルツェゴビナ 特命全権大使 ペロ・マティッチ 閣下
- 祝辞 キルギス共和国 特命全権大使 リスベク・モルドガジエフ 閣下
- 祝辞 パプアニューギニア独立国 特命全権大使 ガブリエル・ジョン・クレロ・ドゥサバ 閣下
- 祝辞 京都府 副知事 山下 晃正 様
- 祝辞 京都市 市長 門川 大作 様
- 祝辞 韓国・大統領直属情報保護委員会 コミッショナー 韓国CSO協会 会長 李 弘燮 様
- 祝辞 京都大学 総長 松本 紘 様
- 祝辞 ロチェスター工科大学 プロボスト(筆頭副学長・副総長) ジェレミー・ヘフナー 様
- 祝辞 天津科技大学 副学長(学長代理) 張 愛華 様
- 記念講演会サイバーフィジカル世界でつくる「京都」美濃 導彦 氏
- 祝賀会
- 祝電・祝辞
- 記念行事
- 京都情報大学院大学 創立10周年記念式
- 最新OS Windows 8のストアアプリ開発
- グーグルがやろうとしていることと,ICTの新地平
- スーパーコンピュータ「京」10ぺタフロップスへの挑戦
- VFXと世界的パラダイムの変化
- ロボット時代の創造
- これからのものづくり〝中小企業の挑戦〞
- 全国同時七夕講演会@KCG-2013年の天文トピックスは大彗星到来
- 鉄道の音から電車運転士教育 システム・シミュレータまで
- コードの未来
- 歓迎アイソン彗星
- イノベーションは止まらない
- 中澤きみ子 ヴァイオリン・リサイタル 〜千の音色に思いを寄せて〜
- 三重奏の柔らかな調べ 「ウィーンのトリオ」
- 摩天楼オペラ 彩雨式 情報化社会と音楽について
- アメリカザリガニ平井のITって面白い!講座
- 若手ゲームプロデューサーズ!ゲームとITの未来
- ボカロとゆるキャラとアイドル 表現の進化系
- PCは娯楽の友!
- 御礼
- 京都コンピュータ学院創立50周年・京都情報大学院大学創立10周年記念式典
- 初代学院長の思い出
- 京都自動車専門学校がKCGグループに
- 京都マンガ・アニメ学会を設立
- 「京都国際マンガ・アニメフェア(京まふ)」共催
- ジャパンエキスポに参加して
- 「初音ミク」の生みの親・伊藤博之氏がKCGI教授に
- IT声優コース&マンガ・アニメコース新設
- 古を語る星ぼし⑤ 客星現る!
- 天文シンポジウム「歓迎 アイソン彗星」
- 「.kyoto」いよいよ2015年から運用開始
- 「MUΣA」コンサート by Nitza
- やさしそうに見える電話番号の難しさ 総務大臣賞を受賞して
- ANIA会長に本学の長谷川統括理事長が就任
- 「カワサキZの源流と軌跡」発刊
- 漢詩「新年作」
- 漢詩「詠大覚寺観月祭」
- KCGチームがマイクロソフト学生ITコンテスト Imagine Cup 日本大会で優勝!
- 京都情報大学院大学初代学長 萩原 宏先生が永眠 学校葬・追悼式を挙行
- 追悼文
- 電子計算機と共に歩まれた2の6乗年
- 情報工学の必要性を熱く語り,行動された萩原宏先生
- 追悼文
- 弔電
- 萩原宏先生を偲ぶ
- 萩原先生の短いコメントに込められた大切なもの
- 中国の文学や歴史に造詣が深かった萩原先生
- 萩原先生の思い出
- 萩原宏先生,有り難うございました
- ご恩に深く感謝
- 「KT-Pilot」の開発でご一緒
- 萩原宏先生を偲んで
- 夫婦ともどもお世話になりました
- 萩原先生の思い出
- 萩原宏先生,ありがとうございました
- 泉下から聞こえる柔らかくまた厳しいご叱声
- 教員転身への礎をくださった
- お菓子で団らんの後の本質突く「一言」
- 萩原先生,また季節の果物を持ってお話に伺います
- 萩原先生から学んだこと
- KT-Pilotのこと
- 新たな木の芽を生み出し,先生に報いたい
- 宇田敏彦先生 追悼
- 仙元隆一郎先生 追悼
- 植原啓之先生 追悼
- KCG365 2013 - 2014
- アキューム22号-23号(2015年発行)掲載広告
- KCGグループ創立50周年
- Vol.21
- Vol.20
- 誕生! 京都情報大学院大学 札幌サテライト
- ゲーム&アニメ
- ANIA京都大会・京都府情報産業協会 10周年記念大会
- 特集 東日本大震災
- 北海道バイク紀行
- カワサキZ1開発責任者・大槻 幸雄氏特別講演会
- 古を語る星ぼし③ 晴明の日食と今年の日食
- 卒業生登場 (株)Tryden 吉田鐘一さん
- 卒業生登場 (株)イビソク 木村寛之さん
- ゆとり教育で不足した学力はどこで補完するのか ~社会人になるために~
- 漢詩 「初弘法( 東寺、一月二十一日)」
- 漢詩 「秋日訪山寺」
- 服装について
- 初代学院長の思い出
- 実践WEBサイト奮闘記
- 老人ホーム見学記
- KCG365 2011
- NEAC-2206が「情報処理技術遺産」に認定。長谷川靖子学院長に感謝状
- 「NEACシステム100」KCGで4機種目の情報処理技術遺産・認定機器に
- 加藤真也さん(情報学科)がMashup Awards U‐23賞を受賞
- 前納一希さん(ネットワーク学科)は「スマートフォン選手権・アプリがいっぱい賞」で3位
- 日本がフランス破り優勝,3連覇! CGアニカップ開催、全国から多数の アニメファンがKCGへ
- 西アフリカのニジェールにパソコンを寄贈IDCE23ヵ国目
- マラウイ共和国駐日大使から,コンピュータ寄贈に対しての感謝の手紙が届く
- 12万円以上の善意,東日本大震災被災者へ 「青海大地震の際の恩返し」留学生らが支援バザー
- 閑堂忌に合わせ、恒例のサマーフェスタ 地域の方々とKCGが交流
- 長谷川利治先生 追悼
- さよなら山本武先生
- アキューム20号(2011年発行)掲載広告
- Vol.19
- 京の表情〜四季彩々
- 日本初「コンピュータ博物館」構想―第二章―
- 風の街 シカゴ
- 特集 学校連携
- 上野季夫先生が百歳
- 上野季夫先生 百寿によせて
- おかえり「はやぶさ君」~奇跡の生還
- 古を語る星ぼし② 浦島太郎とかぐや姫
- 世界標準となった日本の工業製品に学ぶ 川崎重工のZ1
- MICTIプロジェクトを振り返って
- 初代学院長の思い出
- 漢詩 「葵祭 路頭之儀」
- 漢詩 「山寺観楓」
- 米山さんがU-20プロコンで受賞
- 卒業生登場 (株)N.ジェン<東京都渋谷区> 西角 光人さん・岡本 匡史さん
- KCG365 2010
- 閑堂忌に合わせサマーフェスタ2010を開催
- KCGI学長に茨木俊秀氏が就任
- KCGIと韓国・国立済州大学校 デュアルディグリープログラム運営で調印
- 京都駅前校近くに イオンモールKYOTO がオープン
- パプア・ゴロカ大学に「KCG・ハセガワ・ラボ」開設
- アキューム19号(2010年発行)掲載広告
- Vol.18
- 特集 世界天文年
- 日食のはなし
- 世界天文年2009 ~ガリレオから学ぶもの~
- 過去未来の大日食
- 日本初「コンピュータ博物館」構想始動
- 日本初のコンピュータ博物館設立に向けて
- コンピュータ博物館の設立に期待
- コンピュータ博物館の設立について
- 『実物コンピュータ博物館』設立について
- 歴史的価値は確実に残し,教育に反映を
- 「日本初 コンピュータ博物館構想」に寄せて
- 技術を末永く後世に
- 博物館は教育施設としても活用を
- 世界で初めてノート型PCを開発 溝口 哲也氏 講演(要旨)
- 鏡の中の右と左
- 福建師範大学での講義
- 漢詩「早春賦」
- 漢詩「早春偶成」
- 百賀の祝い 米田先生が百歳 KCG一同で祝う
- 米田先生 百歳の誕生会に
- 古都逍遥 最終回 白河校周辺5 ~北辺を訪ねる
- 30年目のベルリン
- 寄贈パソコンが開く世界への扉 パプアニューギニア
- 「日本・ドナウ交流年2009」認定事業 ダンス公演『Dance of Death ~生きるよろこび~』
- 初代学院長の思い出
- 卒業生登場 「日本の標準」づくりへ邁進
- 卒業生登場 「起業家という生き方」
- 3年目を迎えたKCGブログ
- 若い感性,中小企業の力に 学生が府中小企業団体中央会のHP構築
- 全授業eラーニング対応 「休校」はせず 新型インフル発生受け「教育受ける権利」重視
- KCG卒業生 木村寛之さんが「日本情報考古学会 堅田賞」を受賞
- KCG保護者会が結成 サークルやセミナー活動で連携を密に
- 初代学院長に静かに手を合わせ 閑堂忌,記念イベントも盛大に
- 世界初,現役ウィーン・フィル奏者+舞踏コンサート ~IDCE 20周年記念~ クラシック音楽の歴史に画期的一歩
- KCG365 2009
- 学生さんとKCGのコンピュータ
- 小規模大学の将来像の一形態;ネットワークマルチバーシティ
- アキューム18号(2009年発行)掲載広告
- Vol.17
- 次の時代へ 新たな誓い 京都コンピュータ学院創立45周年 京都情報大学院大学創立5周年
- 記念式典 式辞 京都コンピュータ学院創立45周年 京都情報大学院大学創立5周年
- 来賓祝辞 堀場 雅夫氏
- 来賓祝辞
- 記念祝賀会(校友祭典)
- ハーバード大学からの祝詞
- コロンビア大学からの祝詞
- 祝電一覧
- IDCE 海外コンピュータ教育支援活動
- 記念イベント・記念講演会
- そして50年へ
- パイオニア・スピリット 新島襄の生き方から考える。
- 特集 IT業界が求める人材 IT人材の不足~現状と課題~
- 特集 IT業界が求める人材 未来のCIOを育てるために~企業のIT化の促進とCIOの必要性~
- 特集 IT業界が求める人材 IT人材の確保のために~全国ソフトウェア協同組合の取り組み~
- 特集 IT業界が求める人材 IT業界の現在
- 卒業生特集 (株)エヌ・ジー・アイ・エフ 代表取締役 松野誠さん
- 卒業生特集 バルーンネット(株) 代表 井上清貴さん
- 卒業生特集 マッチロック(株) 代表取締役 藤本文彦さん
- 卒業生特集 ベニックソリューション(株) 桂 義幸さん
- KCG京都駅前校への玄関口 変貌遂げる京都駅 相次ぐ商業施設整備
- 古都逍遥 白河校周辺4
- ~京都・異文化交流~ベーグルの魔法
- 京都で一番!―これはびっくり裏京都案内―
- 平安の天文家
- MDDロボットチャレンジ参戦記
- KCGI学長に長谷川利治氏が就任
- 洛陽総合高校,京都聖カタリナ高校と相次ぎ連携事業協定
- 「日本初」のKCGが全面支援 天津科技大に中国初の自動車制御学科
- 四川省大地震 故郷の被災者や復興に支援を 中国人留学生ら市内街頭で義援金集め
- 日韓間サイバーキャンパス実現 KCGIが国立済州大学校と調印
- 世界初,遠隔システムでチェコ・パルドゥビッツェ大学と学術教育交流協定を締結
- KCG365 2008
- 初代学院長の思い出
- 漢詩「述懐」
- 漢詩「喜天津再訪」
- アキューム17号(2008年発行)掲載広告
- Vol.16
- 卒業生特集「最先端の証」
- Q-GAMES キュー・ゲームス-会社紹介
- IT を YouT へ-株式会社日本システムディベロップメント
- KCG同窓会@東京
- 澤田さん
- 漢詩「庭梅開花」「船岡山懐古」「長城懐古」
- 詩を創る,唐詩を教わる
- 京都へ,おかえりなさい。
- 京都まち探訪 伏見
- 古都逍遥 白河校周辺3
- 京都のラーメン考
- ゲーム業界の求める人材を育成するために
- ゲーム業界で活躍する卒業生たち
- ダッカの豊かな子どもたち
- サラエボ紀行
- 済州島
- 天津にて
- RIT紀行
- 教育支援の輪 さらに拡大
- KCG 365 2007年
- 初代学院長の思い出
- 火星のクレーター Miyamoto
- オープンソースカンファレンスがKCGにやってきた!
- オープンソースソフトウェアの魅力
- アキューム16号(2007年発行)掲載広告
- Vol.15
- KCG style 2006 コンピュータの未来を探る
- スコット・ロス氏 特別講演会 「What is Reality?」
- 9時間耐久レースでKCG教職員チーム優勝
- 頑張れば,多くの人が支えてくれる 「kcg.edu」インテグラドライバー 伊藤 裕士さんが引退
- 情報セキュリティの現在 日韓越3ヵ国共同セミナー開催
- 日韓越3カ国共同セミナー パネルディスカッション セキュリティってなに? -健全なユビキタス社会の実現に向けて
- 韓国のユビキタス社会実現に向けたセキュリティ対策
- Security of PKI in Ubiquitous Computing
- マイクロソフトのセキュリティへの取り組み ~Vista OSのセキュリティを通じて~
- 「高度専門士」をご存知ですか?
- 長谷川 靖子学院長が(財)日本ITU協会より「国際協力 特別賞」を受賞―記念のピアノコンサートも
- 財団法人日本ITU協会からの国際協力特別賞受賞に際して―海外コンピュータ教育支援活動―
- 学術交流
- 古都逍遥 白河校周辺2
- 漢詩「看櫻」
- 若い時代を振り返って
- シラーの戯曲を読む
- さよならプルート 冥王星の76年
- 京を生きる プロをめざし京都へ 洋画家・中村晴信さん
- 場違いコラム
- 京都情報大学院大学が第1回学位授与式
- KCGI第一期生が「株式会社At Izumi」設立
- 卒業生紹介 ~株式会社インターネットイニシアティブ 白石陽介さん
- 学院を廻るアルティザンたち 劇団PASSIONE 豊嶋文香
- 鮨
- 初代学院長の思い出
- 初代学院長の思い出 特別編
- 詩があるじゃないか
- アキューム15号(2006年発行)掲載広告
- Vol.14
- 新館竣工・自動車制御学科開設に際して
- 京都コンピュータ学院 京都駅前校新館 設備紹介
- 建築家 寺下 浩 インタビュー
- F1の革新とコンピュータ
- Car IT時代のエンジニア養成を目指して
- ベトナムとの交流について ― ベトナム最大のソフトウェア開発会社と事業提携
- 日韓友情年の推進に向けて
- モザンビークICT学院プロジェクト JICA専門家派遣報告
- ダンス公演 京都府舞台芸術振興事業「海心遊記」に参加して
- 日本画を生きる ― 今中 恵
- 古都逍遥 白河校周辺
- 初代学院長の思い出
- 専門職業人教育の制度的由来について― 日本最初のIT専門職大学院の設置に関連して―
- 世界技術者会議2004 参加報告
- 竹田の岡城と全日本実年ソフトボール大会
- 漢詩「夏日郊行」
- 随筆 冬の実
- 相対論誕生百年と安倍晴明没後千年
- 曜日・干支の起源と計算法
- 宇宙一の力持ち-グレートアトラクター
- ゲームプログラマへの道
- 一台のパソコンから全てが始まる
- ITで経営をデザインする
- アキューム14号(2005年発行)掲載広告
- Vol.13
- 京都コンピュータ学院創立40周年記念式典
- 創立40周年記念式典 学院長式辞 時代を拓く情報処理技術者育成をめざして
- 京都コンピュータ学院 創立40周年に寄せて
- 学問の未来と国の未来を担うコンピュータ
- 京都コンピュータ学院 創立40周年記念式典 祝辞
- 京都コンピュータ学院 創立40周年記念講演 「時代を拓くパイオニア・スピリッツ」
- 京都コンピュータ学院 創立40周年記念講演 「なぜ日本の教育に改革が必要なのか」
- 京都コンピュータ学院 創立40周年記念講演 「平和教育への原動力としての情報技術(IT)」
- 京都コンピュータ学院 創立40周年記念シンポジウム 「歴史を揺るがした星ぼし」
- 京都コンピュータ学院 創立40周年記念講演 「未来を拓く超高速コンピュータ」―コンピュータに何ができるのか
- 日本最初にして唯一のIT専門職大学院 京都情報大学院大学 開学
- 京都情報大学院大学開学に向けて
- 京都情報大学院大学 開学記念式典
- 京都情報大学院大学 開学記念式典 理事長式辞
- 京都情報大学院大学 開学記念式典 学長挨拶
- 京都情報大学院大学 開学記念式典 来賓祝辞
- 京都情報大学院大学 開学記念式典 ロチェスター工科大学からのメッセージ
- 京都情報大学院大学 開学記念式典 コロンビア大学教育大学院からのメッセージ
- 京都情報大学院大学 開学記念式典 イリノイ大学アーバナ・シャンペーン校からのメッセージ
- 京都情報大学院大学 開学記念パーティー
- 京都情報大学院大学設立に際して
- 京都情報大学院大学の設備・概要
- 日本最初のIT専門職大学院で学ぶ
- 京都情報大学院大学「ウェブビジネス技術専攻」のカリキュラム
- 京都情報大学院大学 開学記念式典 メッセージ
- 京都情報大学院大学 開学記念式典 祝電
- 初代学院長の思い出
- 古都逍遥 京都駅前校の北辺
- 漢詩「夏日山居」
- 第3世代携帯電話アプリの開発とゲームデザイン― 日本と世界―
- NAIS発足式
- 小説 「雪見 -城崎にて」
- 校友祭典2003 Pioneer Spirit-KCG
- 創立40周年記念行事
- アキューム13号(2004年発行)掲載広告
- Vol.12
- 創立40周年記念の佳節を迎えて
- グローバルな教育ネットワーク
- 京都コンピュータ学院40年の歩み
- 京都コンピュータ学院 創立40周年記念行事スケジュール
- 私が見たモンゴル国
- 情報学 情報学科4年課程設置に際して
- デジタルシティと異文化コミュニケーション -社会情報学に向けて
- IT革命のパラダイムシフトと情報処理教育
- データベースの理論とその発展
- 情報学科が目指す教育
- The Internet2 - Dance in the Digital Age
- 学院NOW
- 大学崩壊と専門学校の優位性
- 中国のIT産業の現状と大学教育
- 日本語教育におけるオンライン教材の可能性
- 南アフリカ共和国・ヨハネスブルグ 「国連・持続可能な開発のための世界会議」レポート
- 宇宙の誕生と宇宙の未来
- 歴史を揺るがした星ぼし
- 携帯アプリ黎明期のゲームデザイン
- 40年前,日本人の大リーガーがいた!~マッシー村上~
- 古都逍遥 百万遍校周辺
- 初代学院長の思い出
- 漢詩「山寺観楓」「山寺観楓有感」
- ロバート・B・クッシュナー先生追悼
- 老師と大河
- Old Professor and The River (Dedicated to“Kush”)
- デジタルな音楽表現の長所と短所
- 学院を廻るアルティザンたち イラストレータ&CGデザイナー 今崎寛之
- 卒業生紹介 株式会社 CSK 松井博也氏
- アキューム12号(2003年発行)掲載広告
- Vol.11
- 米国同時多発テロに思う
- 京都コンピュータ学院ニューヨークオフィス崩壊当日
- 米国同時多発テロの現場から
- ハーバード・メモリアル・チャーチ 聖書の言葉と説教 2001年10月23日
- 我が都市 New York
- 米国同時多発テロから五ヶ月
- 大学に挑戦する専門学校―教育の危機・就職の危機こそ最大のチャンス
- Japan's System of Post-Secondary Education
- 日本の中等後教育制度(高等教育制度)(邦訳)
- 大学崩壊の時代―学校経営の視点から
- 21世紀のIT教育―本格的IT教育を目指して
- eラーニングの市場動向
- IT時代のプログラミング指南
- すばるをめぐって
- 第5回JAHOU集会を終えて
- KCGキャリア
- 学院NOW
- 初代学院長の思い出 ―思い出は尽きない
- 漢詩「冬夜偶成」
- 古都逍遥 鴨川校洛北校周辺
- コンピュータ・プログラムと著作権
- コンピュータの省エネルギー化
- 形状情報処理について
- ランドマークベースの音声認識において最適な指標を求める方法
- KCG RIT 姉妹校提携5周年を迎えて
- KCGとRITの友好関係を築いて
- 妖怪乱舞 陰陽座
- 学院を廻るアルティザンたち 映像作家 石橋義正
- 卒業生紹介 卒業生が最先端 藤井康彦さん
- アキューム11号(2002年発行)掲載広告
- Vol.10
- 巻頭言 21世紀を迎えて・・IT時代は「情報と頭脳」の時代 ―システムの創造的破壊とソリューション教育を―
- 中国,二大学との教育提携 日本語教育とコンピュータ教育の融合をめざして
- 月下独酌~NEW YORK~
- 地球温暖化研究の現状
- バリ紀行
- IT革命とはなにか
- わたしの考える「IT革命」 その虚実皮膜について
- 「専門家」から「非専門家」へ。―「非専門職」のススメ―
- インターネットと知的財産権法
- 中国のコンピュータ事情
- 海外で新米コンサルタント就職奮戦記 しなやかに あっけらかんと したたかに
- 初代学院長の思い出
- 知恵〔智慧〕の時代
- コミュニケーションのための―きく・話す―
- Y2K, on Z2
- 漢詩「緑陰讀書」「鴨川看白鷺」
- 陰陽師 安倍晴明の見た星
- 古都逍遥 京都駅前校周辺
- 世阿弥二題
- アートスペース紹介 ICC NTTインターコミュニケーションセンター
- はるかなるうみのはて
- 中島修彫刻展
- 卒業生紹介 古都京都に在る,小さな小さな大きい会社!
- アキューム10号(2001年発行)掲載広告
- Vol.9
- 創立35周年を迎えて(1998.11.18)
- 創立35周年記念イベント
- 創立35周年記念式典 パソコン贈呈式
- 海外コンピュータ教育支援活動 スリランカ
- 海外コンピュータ教育支援活動 ブルネイ
- 海外コンピュータ教育支援活動年表(1996年以降)
- 海外コンピュータ教育支援活動 北京・天津・西安
- 35周年記念座談会 新しい高速コンピュータの誕生―TOSBAC 3400 開発の思い出―
- 卒業生寄稿 情報化版 温故知新
- 卒業生寄稿 システムコンサルタントを目指す人達に
- 日本の私学と「専門学校」の概念
- 抽象の力
- 漢詩「初夏偶吟」「秋日郊行」
- 曲阜行 孔孟の跡を訪ねる
- コミュニケーションメディアとしてのコンピュータ
- ゲーム開発科の目指すもの
- 上野季夫先生と輻射輸達論の五十年
- 閑堂忌について-「一身独立の気力」-
- 初代学院長の思い出
- 木版画「人間の位置」
- 小惑星 Shotaro
- 五星聚井
- 21世紀の新文化首都 関西文化学術研究都市の試み
- 京都コンピュータ学院創立35周年記念イベント 最先端マルチメディアイベント
- 卒業生紹介 未知へのチャレンジ精神
- アキューム9号(1999年発行)掲載広告
- Vol.7-8
- 巻頭言 社会・文化の大変容期を迎えて ―文化としてのコンピュータ―
- 海外コンピュータ教育支援活動 ペルーへ
- アフリカ・中東・南米へひろがる海外コンピュータ教育支援活動
- 海外コンピュータ教育支援活動 メキシコからの研修生を迎えて
- 海外コンピュータ教育支援活動 タイ国マヒドン大学に滞在して
- 情報処理教育に求められるもの 4年制情報工学科の発足にあたって
- 二期制実施とカリキュラム改革
- インターネットの発展と私のホームページ作り
- 第15回京都コンピュータ学院卒業研究発表会
- 研究所だより
- 京都コンピュ-タ学院とオペレ-ションズ・リサ-チ
- ADEOS衛星搭載のPOLDERセンサ画像データについて
- 学院ニュース
- 初代学院長から伝えられた言葉
- 漢詩「惜花」「梅雨書懐」
- 詩とのつきあい
- 熊楠の手紙
- 宮沢賢治生誕百年に寄せる 「雨ニモマケズ」入門
- 「日本科学教育学会研究会」京都駅前校で開催される
- 世界最高速のコンピュータを作る
- シンポジウム「降着円盤の基礎物理」 天文の数値計算とコンピュータ
- 天文学のニュートレンド(降着円盤)
- 太陽とその活動
- 新惑星系の発見
- RITの日々
- R・I・Tと本学院との姉妹校提携実現に際して
- 芸術情報学科 学生CG作品
- 卒業生紹介 学院スピリッツ
- アキューム7-8号(1997年発行)掲載広告
- Vol.6
- 海外コンピュータ教育支援活動5周年を迎えて
- ポーランド日本情報大学の誕生
- ジンバブエ現地講習会報告
- ペルーへ向けてパソコン出発
- 対サウジアラビア王国支援 京都講習会
- 宇宙の果てに挑む ―新技術が拓く宇宙のフロンティア
- 出会い 中国の旅から
- 不変埋蔵の原理と動的計画の科学
- 不変埋蔵法とシステム同定
- ダイナミック・プログラミング
- 不変埋蔵法と生物医学への応用
- 遺伝アルゴリズムについて
- 研究所だより
- 有為転変 学院の設備更新に際し人材の育成を思う
- 夢のあるコンピュータの世界を
- システム創造のためのワープロ活用術
- 便利さと人間<性悪説>-個人情報保護のためのラディカルな問い
- 誰にでも使えるパソコン・BTRON~未来のパソコンのあるべき姿を見る~
- 初代学院長の思い出
- 京都コンピュータ学院校友会エグゼクティブクラブ結成式校友会長挨拶
- 京都コンピュータ学院校友会エグゼクティブクラブ国際協力事業推進委員会活動報告
- 就職難・リストラの嵐の前衛的突破法
- X線で見た宇宙
- 危ない小惑星
- 情報の天才-空海という人
- 卒業生紹介 情報化時代の啓蒙家
- アキューム6号(1995年発行)掲載広告
- Vol.5
- 巻頭言 学院創立30周年を迎えて
- 学院創立30周年記念特集 情報の哲学 21世紀のノヴム・オルガヌムを求めて
- 「人工知能と人間」(岩波新書)の著者,京都大学工学部教授長尾真氏に聞く。情報科学的視点は,世界をどう変えるか?
- 人間知性理解の二つの議論 -合理論と経験論
- 心の哲学について
- 孔子とのQAシステム
- 梅棹忠夫『情報の文明学』(中公叢書)を読んで
- 寧夏・内蒙の旅 留学生Y君に寄せる
- 研究への発想・発見・発明,意図した成果・意図せぬ発見,早過ぎる独創は権威ある大家も否定する
- 地上の実験室でクォーク・グルオンプラズマを造る-我々はビッグバン直後に到達できるか
- 狂言を語る 茂山千五郎
- 在京懐京(きょうにありてきょうをおもう) 京に老いてはシルバーシート?の巻
- 研究所だより
- モンタージュの魔術
- 「ナチ宣伝」という神話
- 認知の科学
- 認知革命?
- 脳とコンピュータ ―意識を持つ機械を目指して―
- 認知科学と人間の心理 ―機械の知が超えることのできない人間の知とは何か?
- 人工の目 移動物体識別追尾装置
- スキゾフレニアと世界のまなざし
- 茶碗の音
- 音声コミュニケーションの脳内メカニズム 人工知能が言葉を理解するためには
- 権力・文学・国家保安局
- 宮本正太郎先生をお偲びして
- 岩崎直子先生逝去 京都コンピュータ学院の支柱となった先生の功績と,その生命の永遠さを讃えて
- 初代学院長の思い出 とこしえの夢 ―前学院長,父との別れ―
- 星野恒彦句集「連凧」を読んで
- 漢詩
- 京都コンピュータ学院による海外コンピュータ教育支援活動 関連記事
- 対ケニア共和国コンピュータ教育支援活動 悠久なる大地ケニア
- 対ケニア共和国コンピュータ教育支援活動 花を咲かせる旅
- 対ケニア共和国コンピュータ教育支援活動 ナイロビ講習会
- 学院のみなさんJAMBO!! 京都短期留学 ケニア人研究者・教授16名
- ソフトウェア教育の改善を目指して
- ソフトウェア教育の発展を阻害するもの
- ガーナ共和国訪問記 行く河の流れは
- ガーナ共和国ケープコーストにヤスコ・ハセガワ・コンピュータセンター設立!
- 地球に近づく小天体
- 超新星とその残骸
- 宇宙背景放射とダークマター
- はくちょう座の星々-臨終の星が蘇る
- もう一つの国際交流 伝統文化継承に関する相互補完
- 卒業生紹介 学院スピリッツ
- アキューム5号(1993年発行)掲載広告
- Vol.4
- 京都駅前校舎大講堂の音響設計
- MESSAGE 学生達へ・・・
- 京都駅前校舎竣工記念フェスティバル
- 京都駅前校舎竣工記念式典・海外留学生研修オープニングセレモニー
- 京都駅前校舎竣工記念講演 国際化社会における日本の教育-世界の中の日本 期待される人間像をめぐって-
- 京都コンピュータ学院ボストン校創立者 長谷川由さん米国ハーバード大学大学院の卒業式で代表スピーチ
- 情報とは・情報化社会とは
- 「認知科学」へのいざない
- 情報教育懇話会 情報教育の現状
- 宇宙創世のロマン-アインシュタイン宇宙よりホーキング・佐藤の宇宙へ-
- 聖徳太子は南十字星を見た? 地球の首振り運動
- 生命とは
- 星間物質の化学と生命の起源
- 太陽系の有機物と生命の起源
- 地球生物の起源
- バイオの主役 DNAとは
- 遺伝情報の変化と発がんの機構 DNA修復
- 放射線治療に関連して 生体に対する放射線の影響
- 研究所だより
- 京の伝統芸能 能そして歌舞伎
- 教養としての伝統文化
- C&Cと高度情報化社会
- ヒューマン・インターフェイス
- 人にやさしいコンピュータを目指して
- ペン インターフェース PCについて
- 最先端技術とその応用
- 地球サイズの情報文化創造へ
- ガーナ印象記
- 対ガーナ情報教育振興事業 アクラ講習会
- 香港 ベルリンそしてワルシャワ
- ポーランド共和国文部省からの挨拶
- タイ・ガーナ・ポーランド 海外短期研修生を迎えて
- バートランド・ラッセル 教育論を読んで
- 初代学院長の思い出 京大音研
- 卒業生紹介 青年海外協力隊-ジャマイカ派遣を終えて
- アキューム4号(1992年発行)掲載広告
- Vol.3
- ほほえみのくに
- バンコック・パソコン講習会
- タイ・ベネフィット・ガラ
- タイ教員短期留学
- タイ視察旅行から
- 年間3600人のコンピュータ技術者を養成するために
- 対ガーナ情報教育振興事業について
- 対ポーランド情報教育振興事業について
- スーパーコンピューティングとシミュレーション天文学
- こんにちは星の赤ちゃん
- 宇宙の大規模構造
- パソコンのなかの惑星たち
- 知的財産権とコンピュータプログラム
- 初代学院長の思い出 よき時代の想い出
- 初代学院長の思い出 真の優しさ
- 情報の科学
- 情報科学をめぐって
- コンピュータ・ハードウェア技術の発展
- 情報化社会としなやかなシステム
- マルチメディア通信について
- 情報系システムに求められる知的支援を考える
- 連想記憶モデルによる情報の最適識別
- ニューロ理論の理解のために〈脳の働き〉
- ニューロ(神経回路網)理論による自動制御
- ファジィ理論と応用
- 三次元グラフィックスによる山岳景観の表示システム
- 考古学における土器文様とコンピュータ
- 放射線医用画像の解析
- イギリス文部大臣K・クラーク氏 京都コンピュータ学院を視察
- イギリスにおけるコンピュータと情報技術の高等教育
- 現代詩
- 地球温暖化の諸問題
- オーストラリア大陸縦断 ソーラーカーレースに参加して
- 世界の英語ハイク
- 常磐津を語る
- 京都の自然 海岸の松の緑を守るために幻のきのこ,松露を育てる
- 学院を廻るアルティザンたち-(3) Robert B.Kushner ロバート・クッシュナー
- 卒業生紹介 天草の禅寺コンピュータ和尚
- アキューム3号(1991年発行)掲載広告
- Vol.2
- 宇宙と俳句
- ボイジャー2号の見た海王星
- 宇宙ジェットSS433
- 京都コンピュータ学院による対タイ情報教育振興事業
- 同志社の創立者 新島襄と現代
- 若き日の長谷川繁雄初代学院長
- 1991年の惑星直列
- 悪徳商法雑感
- 世のなか,非線形
- 地球環境の科学
- グリーンハウスエフェクト
- マルチスペクトル衛星画像のコンピュータ解析による雲の研究
- マングローブ
- 衛星による地球モニターシステム
- 東南アジアの環境変化の一断面
- 京都コンピュータ学院NEWS
- 宇宙からの地球探査
- 人工衛星による地球画像の解析について
- 宇宙からの地球環境監視
- レーザーレーダーによる地球大気内のエアロゾル等の探査について
- 海洋探査と水色研究
- 高分解能人工衛星画像の領域分割と認識処理
- 「天文学的数字」ほどの情報処理
- 情報処理教育について
- バイオテクノロジーは何をもたらすか
- 現代中国 コンピュータ産業の現状と展望
- 現代詩
- 京都を語る
- 京都コンピュータ学院ボストン校設立の旨
- 第1回ボストン研修のはじまり -オープニングセレモニー
- 学院を廻るアルティザンたち(2) ロバート・メズベン
- 今後の情報処理技術者に求められること
- THE AUDIENCE
- アキューム2号(1990年発行)掲載広告
- Vol.1
- 創刊巻頭言
- 火星の極冠を計算する
- 火星の白雲の振舞い
- 恒星の固有運動
- 独立独行のひと 初代学院長の思い出
- 初代学院長の思い出
- 京都コンピュータ学院 創立25周年記念式典
- 25年! 熟成されたアイデンティティ 創立25周年記念式典学院長式辞
- 上空700kmからの視点 創立25周年記念式典式辞
- 京都コンピュータ学院は文化を創造する 創立25周年記念式典祝辞
- 学院の慧眼に敬服 創立25周年記念式典祝辞
- 先取りした精神と熱い情熱 創立25周年記念式典祝辞
- 国家試験合格者全国最優秀校としての事実 創立25周年記念式典祝辞
- 国際化に向かう先見性 創立25周年記念式典祝辞
- 創立25周年記念式典 記念講演(抄録)
- 創立25周年記念校友大会 朋友遠方より来る
- 創立25周年記念校友大会 また楽しからずや
- 創立25周年記念校友大会 協賛・協力企業一覧
- コンピュータ技術とその国際性
- 宇宙からの気象観測 スーパーコンピュータとともに
- 情報処理教育に求められること
- 現代詩 早稲田大学同人誌サークル「行李」より
- 都の四季
- 同志社(キリスト教学校)はこうして京都(神仏の街)に誕生した
- 映画のような町
- ショートストーリー Tに捧げるサーモンピンク
- 小面(こおもて)と乙(おと)-能と狂言-
- 対談「文化の交流」
- 学院を廻るアルティザンたち(1)キャロリーナ・デ・ウァールト
- 情報と文化のメビウス環
- 学園歳時記 学院プロモーションビデオ制作日記
- アキューム1号(1989年発行)掲載広告
- Extra
Accumu Vol.5
音声コミュニケーションの脳内メカニズム 人工知能が言葉を理解するためには
京都大学総合人間学部自然環境学科助教授 京都コンピュータ学院講師 松村 道一
物理的振動から神経情報へ
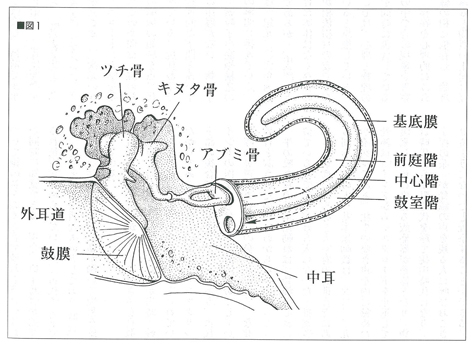
図1 鼓膜と蝸牛管の構造。音声振動は外耳道から鼓膜に到達し,
3種類の小骨の振動を介在して,リンパ液に満たされた蝸牛管に伝えられる。
蝸牛管は,かたつむりのようにぐるぐると2回半巻いている。
この図では,簡略化のため引き伸ばしてある。この蝸牛管の中は,
先端部ほど広くなっていて,ラッパのような管になっている。
この中心部にある中心階に,聴覚神経が存在しているのである。
Kandel「Princeples of Neural Science」より
ヒトのコミュニケーションの仲立ちは,言わずと知れた言葉である。文字の発明は人類の歴史上かなり後のことであるので,ヒトの脳の情報処理に革命をもたらしたのは,話言葉が中心であると考えられている。いわゆる阿吽(あうん)の呼吸と呼ばれるものや,目と目でわかるコミュニケーションというものが存在するのも確かではあるが,今回の話のテーマは,耳から聞こえてくる話し声だけに限ることにしたい。
音声は,勿論空気中を伝わる振動として伝播される。その音が鼓膜に入り,かたつむりのような形をした蝸牛管に伝えられて,神経情報に翻訳されるわけである(図1)。この物理量が神経情報に変換される過程を,もう少し詳しく説明してみよう。
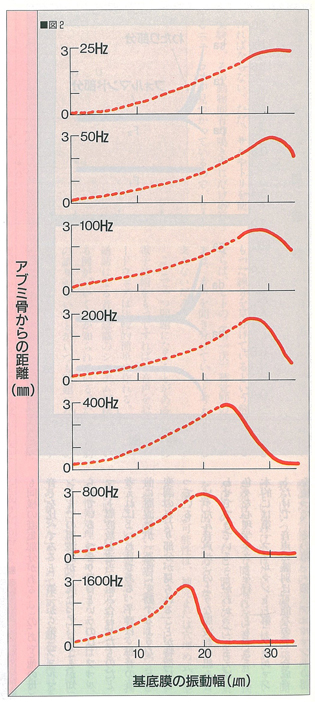
図2 最も大きく振動する基底膜の部分と,音の周波数との関係。
周波数が低いときには,蝸牛管の先端部分の基底膜が最大の振幅を示し(最上部),
周波数が高いときには,アブミ骨に近い部分の基底膜が,最も強く振動する(最下部)。
周波数の情報が,蝸牛管内の位置情報に変換されていることがわかる。
Kandel「Princeples of Neural Science」より
蝸牛管は真っすぐに引き伸ばすと,末広がりのラッパのような管になっていて,中はリンパ液で満たされている。空気中を伝わってきた振動エネルギーは,ここで液体の振動に変換される。金管楽器と同じように,特定の周波数の音は,この管の特定の位置に最もよく振動する部分を作り出す(図2)。この振動が起こっている部分に存在する特別な細胞(有毛細胞)の毛が震え出すと,詳しいメカニズムは省略するが,その細胞にパルス様の活動電位が発生するのである(図3)。
つまり,特定の周波数の振動が,まず蝸牛管の特定の位置の情報に変換される。そして今度は,その位置にある神経細胞を駆動するのである。そうすると,蝸牛管の神経細胞は,ある特定の周波数にだけ応答しているということができる。ちなみにこの神経細胞が発生するパルス電位の頻度は,周波数ではなくて音の強さを表現することになる。通常の音は,単一周波数(つまり純音)とは違い,色々な周波数が混じっている。その周波数に応じて色々な神経細胞が同時に活動するので,言うなれば蝸牛神経は,スペクトルアナライザーのような働きをしているのである。
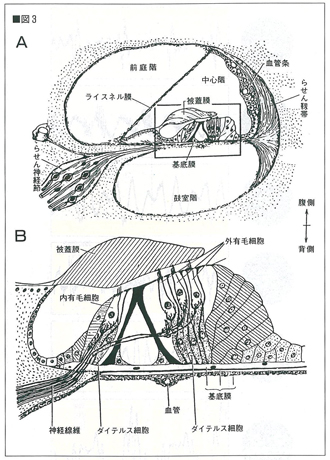
図3 蝸牛管の断面図。A:中心階に,振動を受ける基底膜が存在する。
B:Aの四角で囲った部分を,さらに拡大してある。
被蓋膜と接触している有毛細胞の毛の部分が,振動によって変型すると,
この細胞にパルス状の活動電位が発生する。
入来・外山「生理学」より
音声の認知機構
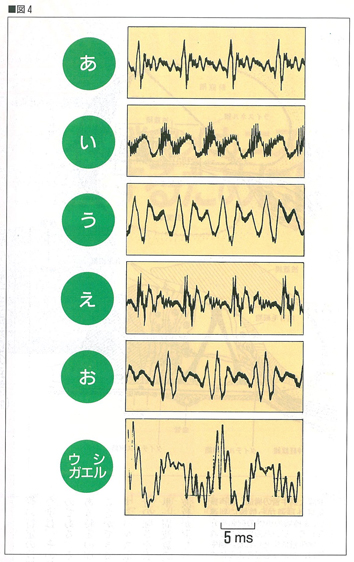
図4 音声のオシロスコープ像。
上から順に,「あ」「い」「う」「え」「お」,
「ウシガエルの鳴き声」
そもそも音声というのは,他の音とどのように区別されているのだろうか。また音響工学的にどのようにとらえ得るのだろうか。音の情報を視覚化する一番簡単な方法は,マイクロフォンでとらえた音声を,オシロスコープでモニターしてみることである。何やら複雑な波形が得られるが,この波形は,音声以外のものとどう区別がつくのか,また音声同士でどう区別がつくのか,残念ながらこのままでは見極めようがない(図4)。
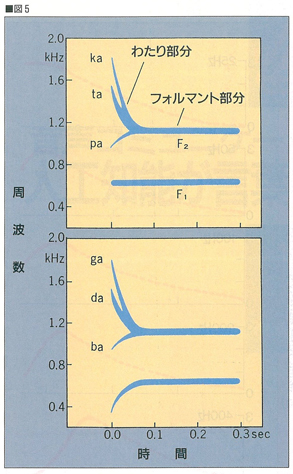
図5 音声のソナグラム。
音声は,周波数が定常状態に保たれている「フォルマント部分」と,
それに先立つ「わたり部分」とから成り立っている。
フォルマント部分が母音を決定し,
周波数変調のあるわたり部分が子音を決定している。
入来・外山「生理学」より
いったんこの波形をフーリエ変換し,時間毎に変動するその波長成分を一目でわかるように表示したのが,ソナグラムである(図5)。
ソナグラムは,縦軸に周波数,横軸に時間をとり,ある特定の周波数のエネルギーの値を,インクの濃さで表している。「あ」という母音は,690Hzの前後に一固まりのエネルギー凝集部分があり(これを第1フォルマントという),次に1170Hz(第2フォルマント),2570Hz(第3フォルマント)の周波数帯にも同様の凝集部分がある。この「あ」と他の母音とを比べてみると,第1から第3フォルマントまでの周波数が,異なっていることが知られている。つまり母音というのは,フォルマント周波数を適当に組み合わせたものだと考えればよいわけである。子音は,母音の直前に周波数が一過性に変動するような,FM変調のわたり部分が見られることが特徴になっている。
いったん音声がこのような周波数の組み合わせでできていることがわかってしまえば,色々な心理学テストを行うこともできる。基本的には第1フォルマントと第2フォルマントだけで,音声の識別は可能なので,合成音を使って,その第1・第2フォルマントの周波数を変えてやると,それに応じて聞こえる母音の種類が変わってくる。(図6)には,アメリカ人の母音の聞き取り領域を示してある。「あ」とも「お」とも聞こえる領域があるのは,大変面白いことである。
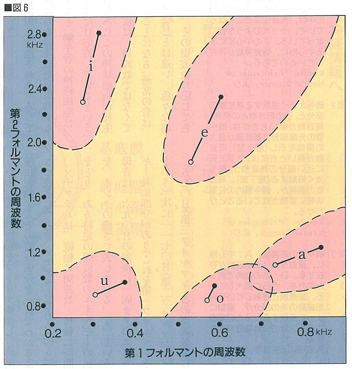
図6 ある特定の母音を識別できる,第1フォルマントと第2フォルマントの領域。
白丸は男性の平均,黒丸は女性の平均。
「a」と「o」は,どちらとも聞こえる部分がある。
入来・外山「生理学」より
蝸牛管から出た神経線維は,脳に入り色々な中継核を経て,大脳皮質聴覚野に投射している。中継核というのは,単に音情報を中継しているだけではなくて,左右の音を聞き分けたり,位相のずれを利用して音源の方向を言い当てたりするような機能を持っている。しかし今回の音声の認識機構の話とは,直接関係がないので省略する。聴覚野には,このような音声に対して特異的に応答するニューロンがあると考えられている。直接ヒトの脳に電極を刺して,そのようなニューロンが存在するかどうか今のところ調べる技術がないので,あくまでも推論であることをお断りしなければならない。ただ,サルやトリを使った実験で,その動物固有の鳴き声にだけ応答するニューロンが見つかっているので,ヒトにもその固有の音声に応答するニューロンが存在することは,十分に予想できるのである。第1次視覚野のニューロンが,特定の傾きをもった線分を見分けているという解釈をするならば,ヒトの(第1次)聴覚野のニューロンは,音声を聞き分けていると考えても差し支えないだろう。
ここで一つ問題になることがある。現代の電子技術をもってすれば,音声を認識するハードウェアは比較的簡単に作れる。実際に,通話による音声認識のシステムが稼働している例が,いくつか知られている。ただし判別の誤りが多いことがいつも問題になるのである。これは人によって声色が違うというような,単純な問題ではない。ハードウェアの精度がいかに向上しても,この誤りはいかんともし難いのである。
根本的な問題は,ヒトがいつも正確に発音記号どおりの発音をしているわけではないことにある。前後の言葉につられて,あいまいな発音をしていることの方が多いのである。時には,別の音声の範疇に入ってしまうこともある。先程も述べたように,正常な発音をしていても,「あ」と「お」には重なる部分があるのである。初めて習う外国語が非常に聞き取りにくいのも,ここに問題の一端がある(図7)。この問題の解決のためには,1音節ごとの分析だけでは不十分なのである。
図7 日本人の耳には,フランス語はどう聞こえているか。
心理学テストによる明瞭度の違い。
左:5種類の日本語母音を聞き分けたときの判別能力を,
統計的な距離として,XY座標にプロットしてある。
お互いの距離が遠い程,明確に判別できたことを示している。
右:8種類のフランス語の母音に対する,同様の統計的距離。
日本人には,「e」と「ε」の違いが,ほとんど判別できないことがわかる。
小嶋(1986)より
ウェルニッケの言語野と言語情報処理
つまり一つの音節が分析できたことだけでは,言語が理解できたことにはならないのである。いくつかの音節が集まって,初めて意味のある言葉になるのは当然のことであるが,我々はいつもクリアで正確な言葉の発音を聞いているわけではない。それでは,あいまいな発音やノイズで聞き取れない音声から,我々はどのようにして間違いのない正しい言葉を選び出すのであろうか。
第一の可能性は,補完または穴埋め式のやり方である。「_ンピュータ」というあいまいな発音を聞いた途端に,我々は直ちに「コンピュータ」という言葉を思い浮かべるだろう。我々の脳は,わからない部分があるからといって,情報処理をやめてしまうわけではないし,あいまいな部分に関していちいち五十音順に「あ」から「ん」まで当てはめて,順番に検討をしているわけでもない。あらかじめ言葉として成り立ち得る答を用意して,脳は待ち構えているのである。言うなれば,パターン照合のような作業をしているのである。この辺りは,最近のワープロのスペルチェッカーのような機能と似ていると考えれば,聴覚野で行われている言語処理の機能も理解しやすいのではなかろうか。この場合は,できあがった文章を後からチェックするのではなくて,オンラインの処理である。最近はやりのニューラルネットの技術でも,この辺の問題はどうにかクリアできるようである。
しかし例えば「れい_うこ」であれば,これは「冷蔵庫」か「冷凍庫」かすぐには判定がつかない。第二の可能性というのは,明らかに文脈に依存するやり方である。この言葉の前後で話されている内容によって,初めて言葉が一意的に決定されるのである。ここまでくると,言葉の貯蔵庫から引っ張り出してきた単語とのマッチングだけでは間に合わない。言葉と言葉をつなぐ構文(文法)と,その意味内容が重要になってくる。
この辺りの情報処理を担うのは,ウェルニッケの言語野と呼ばれる領域であり,90%のヒトでは左半球の側頭部に存在する。5%は右半球,残りの5%は両半球に言語野がまたがっている。この偏りは,利き手に関係していると言われている。左利きの人は,右半球に言語野をもつことが多く,成長の過程で右利きに矯正された人は,言語野が両半球にまたがって存在することが多い。
脳梗塞や脳出血でこのウェルニッケの言語野に傷害が起こると,音は聞こえているのに,言葉の意味がわからない,という障害が生じることが知られている。PET(ポジトロン・エミッティング・トモグラフィ)と呼ばれる装置で脳の活動を調べてみると,朗読を聞いているときには,明らかに左半球のウェルニッケ言語野が活動していることがわかる。また音楽を聞かせると,右半球に活動が偏るのも面白い現象である。
ごく最近の研究で,正常な人のウェルニッケ言語野や,後で述べるブローカ言語野に,1cm間隔で電極を埋め込み,電気刺激をするという実験が行われた。色々な言語テストをしている間に電気刺激を与えると,言語機能が障害されるが,その障害は刺激部位ごとに少しずつ異なっていた。つまり一口に言語野と呼ばれている広い領域にも,少なくとも1cm2位の単位で,少しずつ機能の異なったモジュール構造がある,ということがわかってきたのである。
言葉の意味とメタ認知
言語は,書かれていることがすべての情報ではない。俗に「行間を読む」・「眼光紙背に徹す」と言われているが,言葉というものはいくらでも深読みができるのである。比喩で語られていたり,その言葉から何となく連想がわいてきたり,一つの文が二重の意味にも三重の意味にも読めることがある。例えば次のような不完全な文があったとする。
1 ぶらぶら_んぽ
2 くろい_んこ
解読をすると,1の答はもちろん「ぶらぶら散歩」,2は「黒いあんこ」または「黒い金庫」であるが,1と2の文が並んでいると,何となく他の連想をしてしまいそうな気がするから,言葉とは不思議なものである。
俳句は5・7・5の17文字から成り立っているが,これは俳句には17バイトの情報しかないということではない。「古池や」という1節だけで,我々の頭の中には古池のビジュアルイメージが広がり,この句を読んでいる人の生活体験に従って,様々な連想や感情がわいてくるのである。それだけでも,5バイトをはるかに上回っていることは間違いない。ましてやそれに続く12文字の意味を組み合わせると,とてつもなく広大な詩的空間が現れてくるのである。
このように,言語は単なる情報伝達のメディアであるわけではなくて,我々の精神状態の意味的(Semantics)再構成を創り出す手段として利用されているのである。言うなれば,言葉の解読作業の上に立って,そのすべての意味を理解しようとしている意識が,脳のどこかに存在するということだろう。これをメタ認知と呼ぶ人もあるし,平たく言えばこれが知性そのものであるわけである。
一般的に情報処理の過程を眺めていると,処理されるデータには,入口があって出口があるという,極めてすっきりした体系が存在している。しかしどんな処理体系でも,すっきり理解できるとは限らない。処理される言語に眼を奪われて,情報の入口から出口まで,言葉の行く末だけを追い求めているとしたら,こんなメタ認知の存在には永遠に気が付かないだろう。そんな研究者には,単に情報として処理されていくデータより,一段高いところに位置する知性の存在が,眼に入らないからである。
残念ながらこのメタの情報処理を行う脳の領域は,まだ解明されていない。脳の中には低次の情報処理をする領域から,高次の処理をする領域まで,色々な階層性があることがわかってきている。すべての感覚情報は,最終的に大脳皮質連合野に到達することがわかってきたので,そこで最も高次の情報処理が行われていると推測することも可能である。勿論この領域が知性そのものかどうかは,検討の余地が残っている。脳は典型的な分散処理のシステムであるので,この連合野を破壊したところで,知性そのものを目の前に取り出すことはできないのである。
今世紀最大の数学者と言われているゲーデルは,「ある公理系からできあがった世界には,証明することも否定することもできない定理が必ず存在する」ことを証明してしまった。これはゲーデルの不完全性定理と呼ばれており,この難解な定理を,一般化してもう少し砕いて説明すれば,「どんな立派な理論を作っても,その理論からは証明できない対象が必ず存在する」ということになろうか。
だとすれば,ニューロンの機能をもって脳の機能を説明しようとしても,説明不可能な事態が生じ得るわけである。科学というものが,徒労に終わる可能性もあるのである。同じことは人工知能の研究についても言えるのであって,メタレベルの処理は,低レベルのプログラム言語では処理できないことになるかもしれないのである。コンピュータ技術の中で,将来とも一番厄介な課題が,このメタ認知の問題であろう。プログラムを自動的に作るソフトウェアを開発しようとしても,誰がその業務を監督し采配するのかという問題を,解決しないといけないわけである。この「全能の神様」は,自動化ソフト自身の中にいるわけもなく,ましてやOSがそのようなものに関知しているはずはないだろう。計算機科学の一番奥底は,いまだに謎のままである。
言語の発声とブローカの言語野
勿論音声コミュニケーションは,「聞く方:ヒアリング」だけでは成り立たない。もう一つ大事な「話す方:スピーチ」の要素がある。脳の中でもこの二つは分業していて,話す時はもっぱら前頭葉の「ブローカ」の言語野という領域が働いている。このブローカの言語野も,ウェルニッケの言語野と同じく,大多数の人で左半球優位である。
このブローカの言語野でも,ウェルニッケの言語野に勝るとも劣らない,複雑な機能が営まれているのであるが,残念ながら紙面が尽きてしまったので,この話はいずれまたの機会に譲ることにしよう。
言語の情報処理は,ヒトの脳の最も発達した機能であるが,まだまだその実体はよくわかっていない。その解明のためには,言語認知の機構の研究や,神経科学のさらなる進展が望まれる。最後に,この方面の研究について,もっと知識を得たいという人には,次の本を推薦しておきたい。
「脳とコミュニケーション」(シリーズ脳の科学)岩田 誠著 朝倉書店
「人工知能と人間」長尾 真著 岩波新書